This is not a particularly difficult utility function the powerful universe of pandas has to offer if one has had a good rest and is well hydrated.
However, if you are a programmer like me, its probably your 433rd run of your jupyter notebook at 00:10 and for the love of God you can not seem to understand what your colleague’s reason for using the obscure groupby utility functions below:
Well, you can easily go to pandas documentation here but I did find that a little bit to scant for me. And, at the time of writing this article, the darling of the programming, StackOverflow did offer some solutions that were entirely too long for my bloated mind that still needed to run and verify 300 more lines of code to absorb.
So for fast absorption what groupby(…).first() does is as usual it groups by the column(s) you indicate then the value it picks for its aggregation is the first one from each grouping.
Let me show you, visual is always better anyway:
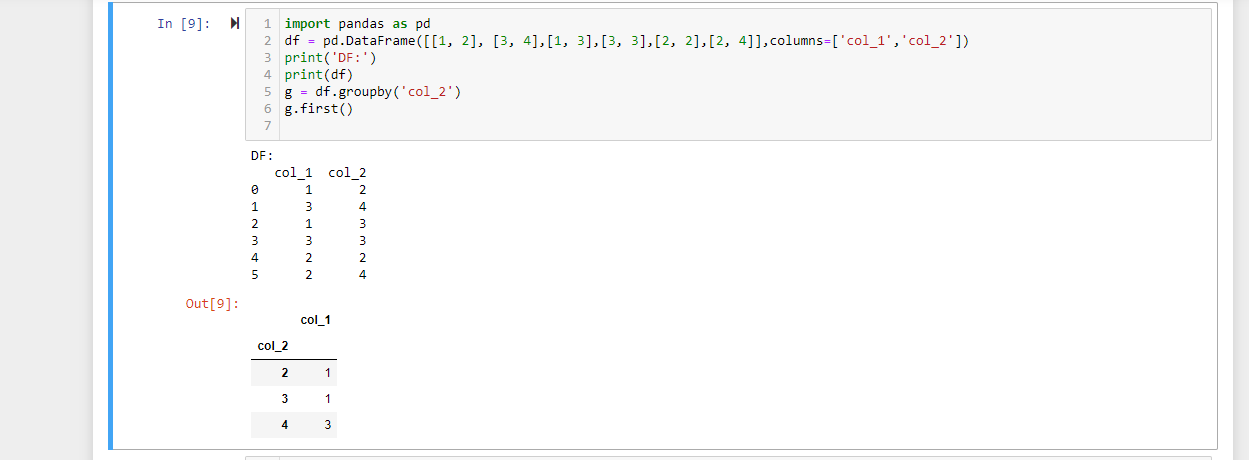
As you can see above we are aggregating on ‘col_2’,an for example the value for 2 is 1 in the aggregation because for all the 2’s that appear in ‘col_2' with values[1,2] respectively for ‘col_1’, the first 2 has a value for ‘col_1’ that is 1.
If you haven’t understood that read it again 5 more times. If nothing still, just know its time for bed, you’ll read this again tomorrow. I promise you it’ll click then.
And as you can imagine it is the same for .last(), just read the explanatory sentence and replace anywhere you see the ‘the first 2’ with ‘the last 2’ and ‘value for ‘col_1’ that is 1' with ‘value for ‘col_1’ that is 2’.

Good. Great. Now you can continue debugging. Even with 5 reads, I think this should have be a 2 minute-read or shorter depending on the last 10 hours of your life.
Good night.